






What is Edge Computing?

Computing is no longer exclusive to the domain of dedicated computing devices such as computers or phones. If you are reading this, chances are you have interacted with a smart device of some sort that can process data and connect to the internet directly - this is an example of edge computing. In this post, we break down what edge computing means and why it’s going to be massive for the future of IoT.
Edge computing is arguably the most defining IoT trend of recent times. Edge computing is believed to mark the beginning of a new era for IoT technology. But to the average joe, edge computing is arguably just an empty term that doesn’t make a lot of sense. So, we thought we would publish an easy to digest rundown of what edge computing means and why we think it is going to be absolutely critical for the future growth of IoT technology.
Background
To understand edge computing, it’s essential that we understand how a basic internet of things network operates. In essence, the idea behind the internet of things is to decentralise data collection, processing and transmission.
It basically refers to a system where many individual components, placed at various locations within the network, including the fringes, are able to participate in the computation of data. In real life, this translates to faster and more responsive feedback loops, higher operational convenience and a significantly more refined and sophisticated experience from the user’s standpoint.
If that sounds a bit abstract and generalised, that’s because what we’re talking about here encompasses a seriously wide range of possibilities - IoT technology could refer to anything from a basic smartwatch that can track your heart rate and activity levels to something orders of magnitude more sophisticated like a remote management system at a manufacturing plant.
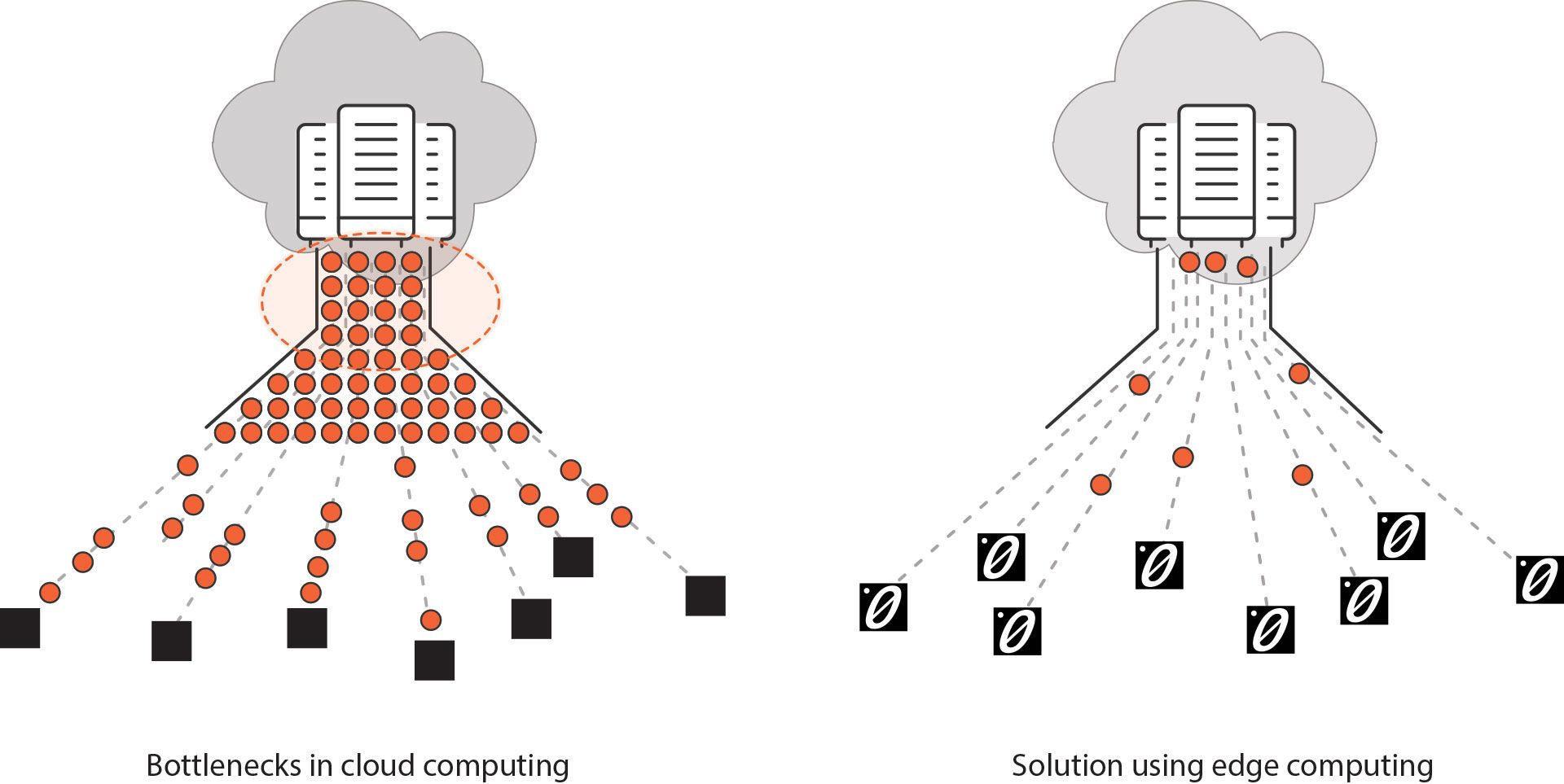
Traditionally, an IoT network comprises end devices that are positioned at various locations in the network, which relay information back and forth through a central data processing centre. Alternatively, the data centre could be cloud-based - which means the edge devices are all connected to the cloud, where the bulk of the information processing takes place.
Edge Computing - What does it mean?
Gartner defines edge computing as “part of a distributed computing topology where information processing is located close to the edge, where things and people produce or consume that information.”
Edge computing is actually exactly what it sounds like - computing processes that take place closer to the edge of a network - i.e information processing that is more distributed and takes place at multiple locations within the network, without having to go through the central data processing centre or cloud.
This makes sense on multiple levels - When more processing happens on the edge of networks, the lower the strain placed on the centralised server, which in turn reduces latency throughout the entire network. This kind of setup reduces lag time and makes for a more responsive and smooth functioning network.
How does edge computing work?
Let’s try and understand edge computing through a couple of examples - let’s imagine a network of sensors that monitors an oil plant for spills and other hazards. Now, in the traditional IoT paradigm, if one of the sensors picks up clues pointing to an anomaly, it would relay this information to the central data processing centre or the cloud, which would then relay signals back to the same or a different edge device to initiate some sort of a mechanism to deal with the hazard - like an automatic cut off signal.
With edge computing, it would work a little differently - say the sensor picks up signals that point to an impending catastrophe - the processing of this information takes place closer to the device that picks up the data, and the feedback loop is affected sooner. It’s not hard to see why an edge computing paradigm would make a lot more sense for a system like this - a quicker response in this case makes a world of a difference and could even save lives. Granted this was a bit of an extreme case scenario, but even when lives aren’t at stake, edge computing is preferred for the same reason - faster response times and reduced latency periods.
Let’s look at another example - imagine a network of IoT security cameras and sensors that form the security system of a building. Let’s assume that the cameras pick up all sorts of raw footage, which is then analysed to detect motion or some other salient feature, and then sorted based on that. That is, only footage with detectable movements are stored on to the server - the rest is discarded. If this sorting has to happen on the cloud or a centrally located server, then it would imply that tons and tons of raw footage has to be relayed over the internet, which would require mind-boggling amounts of bandwidth. Alternatively, if the cameras are equipped with a mechanism to sift through the footage and vet out the footage where no motion is detected, it would save massive amounts of bandwidth and place a significantly lower amount of strain on the server and in turn, the entire network.
This is why edge computing is creating the kind of stir that it is in the IoT world - it spells all sorts of positive omens for the future of IoT.
Advantages of edge computing
Edge computing has a few very significant advantages over more traditional, server or cloud-based network modalities.
Savings
In the previous section, we saw an example of a basic IoT-based setup that benefits tremendously from an edge computing paradigm. We saw how edge computing enables lower bandwidth use and more intelligent expenditure of server resources. Bandwidth and cloud resources are both limited quantities and represent a significant monetary investment on the part of the client.
With billions of new IoT devices predicted in the near future, a significant chunk of computation will need to happen at the edge.
Improved performance
Edge computing makes for reduced latency periods. Because the edge device doesn’t have to relay information back and forth from a cloud, lesser time is required to process a similar kind of operation.
By bringing more operations closer to the edge of a network, latency times can be reduced.
New functionality
Moving operations to the edge can often open up entirely new ranges of functionality that weren't available before due to the constraints of a larger network. Edge computing, for example, opens up the possibility of more processes being conducted in real-time.
Are there any drawbacks to edge computing?
There are two main drawbacks to edge computing.
Firstly, with information being processed at more locations within the network, there are more potential “footholds” for malicious elements to breach the system. Although work is being done in this regard, security does pose a challenge to edge computing.
Secondly, moving more processing to the edge of a network necessitates higher investment in edge hardware. This can be prohibitive for small-scale IoT operations.
Keep Reading




About the author

Runar Finanger
CMO
Runar, the co-founder and CMO of ONiO, adeptly connects product innovation to customer desires. Championing brand-building, he heightens consumer awareness and consistently propels brand preference through diverse channels.
